Le problème : comment les IA explorent le web
Les grands modèles de langage (LLM) comme ChatGPT, Claude, Gemini ou Perplexity disposent de leurs propres robots d'exploration qui crawlent le web pour alimenter leurs bases de connaissances ou répondre à des requêtes en temps réel. Ces crawlers se comportent différemment des robots des moteurs de recherche traditionnels : ils ne cherchent pas des signaux SEO techniques, ils cherchent du contenu compréhensible et structuré.
Un site web moderne présente un défi particulier à ces crawlers IA : le HTML est encombré de navigation, de publicités, de scripts, de composants UI répétitifs. Extraire le contenu pertinent d'une page requiert des heuristiques complexes — et ces heuristiques peuvent se tromper, omettre des sections importantes ou inclure du bruit non désiré dans ce que l'IA va apprendre de votre site.
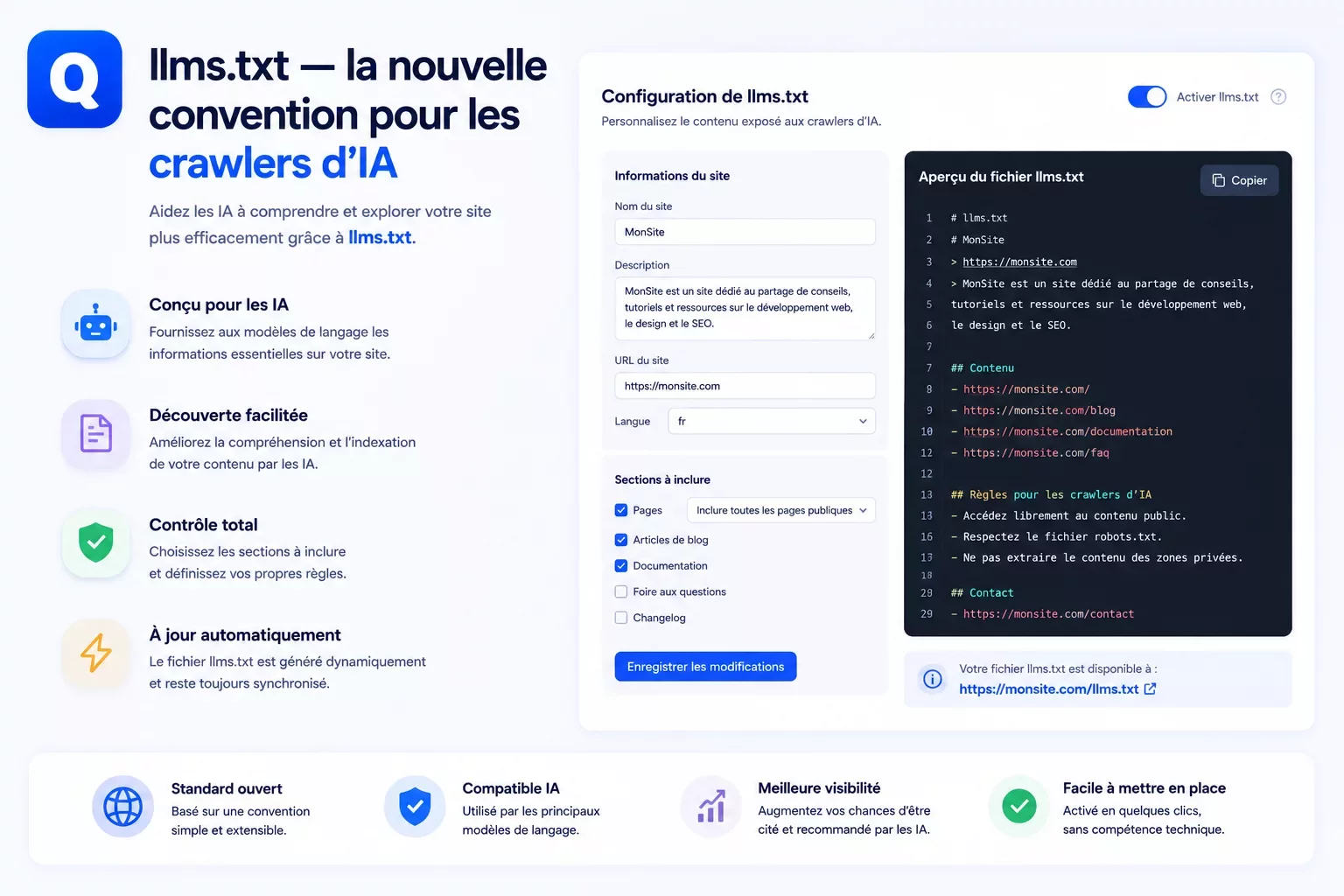
C'est pour résoudre ce problème que la spécification llms.txt a été proposée sur llmstxt.org. Elle suit la même logique que robots.txt : un fichier à la racine du site, lisible par les crawlers, qui leur dit ce qui est important et comment le site est organisé.
Format du fichier llms.txt
Contrairement au XML du sitemap ou à la syntaxe propriétaire de robots.txt, llms.txt est du Markdown structuré — un format que les LLMs lisent et comprennent nativement. Sa structure est intentionnellement simple :
# Nom du site — description courte
> Phrase de résumé décrivant l'activité ou l'objet du site.
## Pages principales
- [Accueil](https://exemple.com/): Page d'accueil du site.
- [Documentation](https://exemple.com/documentation/): Documentation technique complète.
- [Installation](https://exemple.com/installation/): Guide d'installation pas à pas.
## Articles récents
- [Titre de l'article 1](https://exemple.com/article-1/): Résumé en une phrase.
- [Titre de l'article 2](https://exemple.com/article-2/): Résumé en une phrase.
## Blog
- [Blog](https://exemple.com/blog/): Tous les articles publiés.Le fichier est accessible à /llms.txt et servi avec le type MIME text/plain. Sa taille recommandée est inférieure à 500 lignes — au-delà, certains LLMs peuvent tronquer leur lecture. La concision est une qualité dans ce format.
llms.txt vs robots.txt — deux rôles complémentaires
Les deux fichiers ont des rôles distincts et se complètent :
robots.txt— Définit les règles d'accès : quelles URLs un crawler peut visiter, lesquelles lui sont interdites. C'est un mécanisme d'exclusion.llms.txt— Définit la structure du contenu : quelles pages sont les plus importantes, comment le site est organisé, ce que chaque page contient. C'est un mécanisme d'orientation.
Un site peut avoir un robots.txt permissif (autoriser tous les crawlers partout) et un llms.txt qui guide les IA vers les contenus les plus pertinents. Inversement, un site peut bloquer certains crawlers IA dans robots.txt tout en maintenant un llms.txt pour ceux qu'il autorise.
Agents utilisateurs des principaux crawlers IA
Si vous souhaitez contrôler l'accès de crawlers IA spécifiques via votre robots.txt, voici les agents utilisateurs à connaître :
- GPTBot — OpenAI (ChatGPT, GPT-4o…)
- ClaudeBot — Anthropic (Claude)
- Google-Extended — Google DeepMind (Gemini, modèles Google AI)
- PerplexityBot — Perplexity
- meta-externalagent — Meta AI (LLaMA, Meta AI assistant)
- Applebot-Extended — Apple Intelligence
Pour bloquer un crawler IA spécifique tout en autorisant les autres, la directive robots.txt est ciblée par agent utilisateur :
User-agent: GPTBot
Disallow: /
User-agent: *
Allow: /L'éditeur visuel de robots.txt intégré à QuietCMS permet de configurer ces règles sans connaître la syntaxe exacte du fichier.
llms.txt et sitemap XML — complémentarité
Le llms.txt ne remplace pas le sitemap XML. Les deux coexistent et remplissent des fonctions différentes :
- Le sitemap indique quelles pages existent —
llms.txtindique ce que ces pages contiennent - Le sitemap est traité par des algorithmes de crawl —
llms.txtest compris directement par les LLMs en tant que texte - Le sitemap est formaté pour les machines (XML) —
llms.txtest formaté pour les modèles de langage (Markdown lisible)
La combinaison des deux offre aux IA une image complète de votre site : quelles pages existent et quand elles ont été mises à jour (sitemap), et quel contenu trouver à chaque URL et pourquoi c'est pertinent (llms.txt).
Génération automatique dans QuietCMS
QuietCMS génère automatiquement un /llms.txt à chaque mise à jour du contenu, sans configuration. Le fichier est structuré en trois sections :
- En-tête — Nom du site et description courte tirés des paramètres généraux du back-office
- Pages principales — Liste des pages statiques publiées, avec leur méta-description comme résumé — un champ déjà rempli pour le SEO traditionnel, réutilisé ici sans surcoût
- Articles récents — Les N derniers articles publiés, avec leur catégorie et méta-description (N configurable dans les réglages SEO)
Les pages et articles marqués noindex sont exclus du llms.txt, pour les mêmes raisons qu'ils sont exclus du sitemap : vous ne souhaitez pas que des contenus que vous masquez des moteurs de recherche soient indexés par les IA.
Adoption et perspectives en 2026
La spécification llms.txt reste émergente — elle n'est pas encore un standard officiel du W3C ou de l'IETF. Son adoption progresse cependant rapidement parmi les sites de documentation, les outils SaaS et les plateformes techniques. Des frameworks comme Astro et des outils comme Mintlify ont commencé à intégrer la génération automatique de llms.txt dans leurs workflows.
L'implémenter dès maintenant présente un risque quasi nul (c'est un fichier texte de quelques kilooctets, sans impact sur les performances) et un potentiel de visibilité croissant à mesure que l'usage des assistants IA pour la recherche d'information se généralise. C'est l'équivalent de l'adoption précoce de sitemap.xml au milieu des années 2000 : le coût d'entrée est minimal, le bénéfice potentiel est significatif pour les sites qui s'y mettent en avance.
Articles similaires

JSON-LD et Open Graph par article
QuietCMS génère automatiquement JSON-LD (Article, WebPage, BreadcrumbList) et Open Graph par page et article.
Le protocole Sitemap XML — standards et bonnes pratiques
Tout comprendre sur le protocole sitemap XML : balises loc, lastmod, priority, extensions image/video, et comment QuietC…
Gestionnaire de redirections et fil d'Ariane
QuietCMS inclut un gestionnaire de redirections 301/302 et un fil d'Ariane automatique configurable.