La bibliothèque de classes core/ de QuietCMS
Tour d'horizon des 20 classes PHP de la bibliothèque core/ de QuietCMS et leurs responsabilités.
Principes d'architecture flat-file, routeur PHP, stockage JSON et structure interne de QuietCMS.

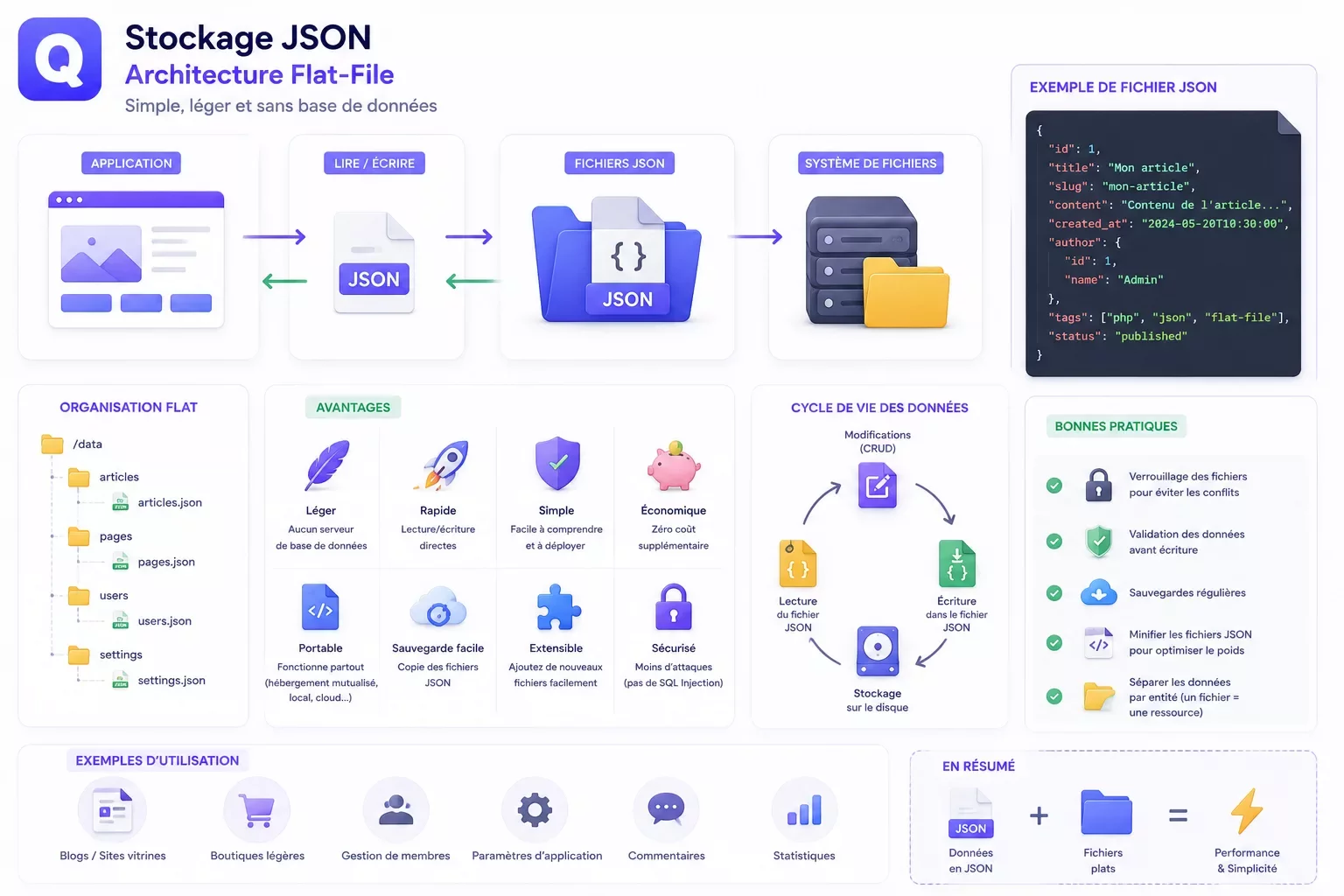
QuietCMS repose sur un principe architectural rare dans l'écosystème des CMS modernes : l'absence totale de base de données relationnelle. Pas de MySQL, pas de PostgreSQL, pas de SQLite. L'intégralité du contenu — pages, articles, catégories, paramètres, utilisateurs, médias — est stockée dans des fichiers JSON structurés sur le système de fichiers. Cette décision de conception n'est pas un compromis : c'est une philosophie délibérée, construite autour de trois impératifs : la portabilité, la lisibilité et la simplicité opérationnelle.
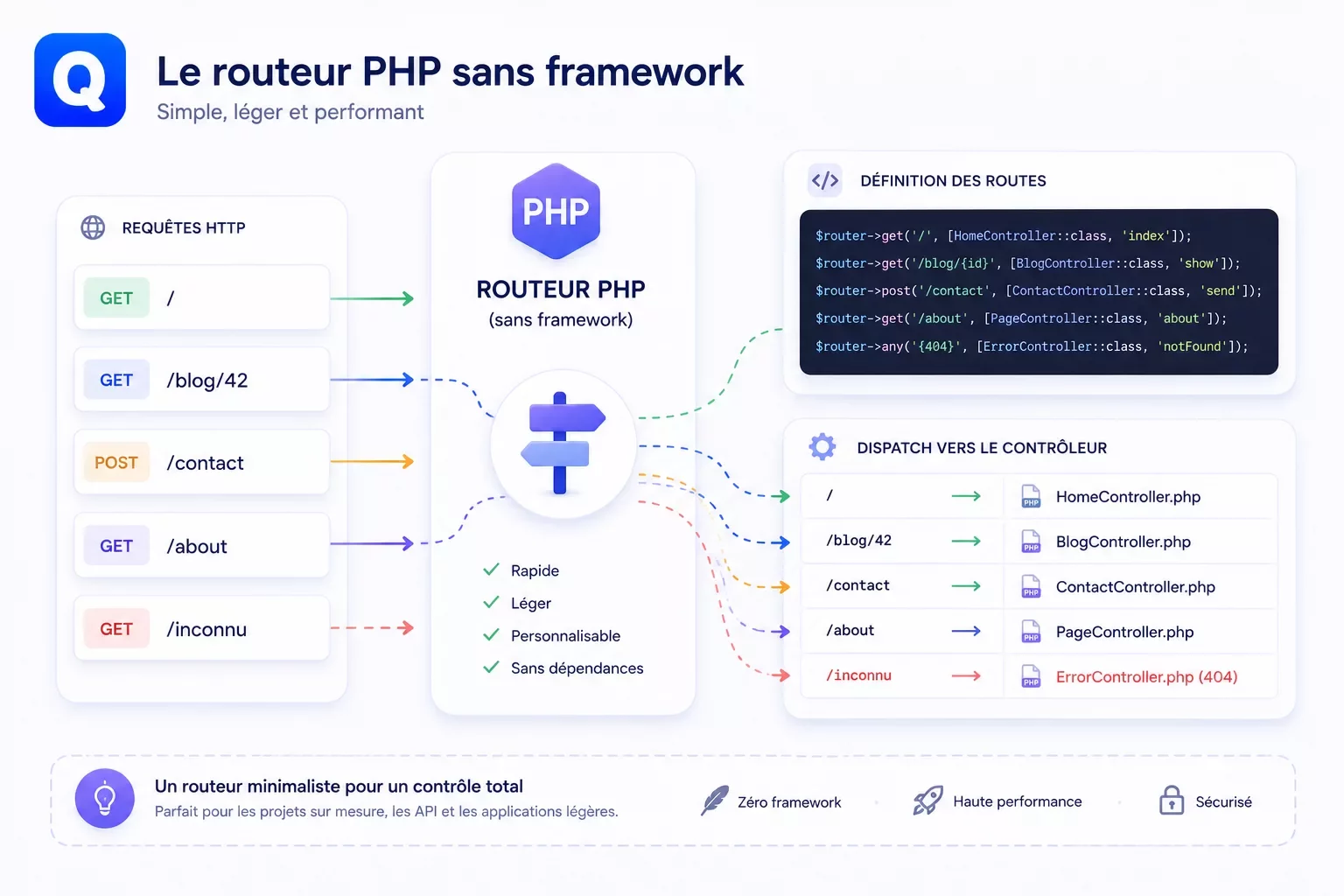
Toutes les requêtes entrantes sont capturées par un fichier index.php unique, grâce à une règle mod_rewrite dans le .htaccess (ou son équivalent Nginx). Le routeur analyse le segment d'URL, identifie le type de ressource demandée — page statique, article, archive de catégorie, blog, flux RSS, sitemap — et dispatche vers le contrôleur approprié.
Le routeur de QuietCMS évalue les routes dans un ordre défini, du cas le plus spécifique au plus générique. Il vérifie d'abord les routes réservées (/sitemap.xml, /robots.txt, /llms.txt), puis les redirections configurées, puis la correspondance avec les slugs de pages, d'articles et de catégories. Ce système à règles explicites est entièrement auditable en quelques minutes de lecture — il n'y a ni magie, ni résolution dynamique opaque.
L'absence de framework de routage externe signifie zéro surcharge de chargement de classes, zéro résolution de dépendances, zéro réflexion PHP. Une requête typique vers une page statique complète son cycle en moins de 5 ms sur un serveur avec OPcache activé.
Chaque entité du CMS correspond à un fichier JSON dans le répertoire content/. Un article de blog, par exemple, est stocké dans content/posts/{slug}.json et contient tous ses champs dans un objet plat : titre, slug, catégorie, date, statut, auteur, contenu HTML, méta-description, Open Graph, JSON-LD personnalisé, etc. Il n'existe pas de table de jointure, pas de clé étrangère, pas de normalisation. Chaque fichier est auto-suffisant et lisible par un humain.
Ce choix a plusieurs conséquences pratiques immédiates. Premièrement, le contenu est versionnable avec Git : un git diff sur un fichier JSON montre exactement ce qui a changé dans un article, avec attribution et historique complet. Deuxièmement, la sauvegarde se résume à copier un dossier — pas de dump SQL, pas d'export, pas de script de migration. Troisièmement, le débogage ne nécessite aucun client de base de données : un éditeur de texte suffit pour inspecter n'importe quelle donnée du système.
Les listes (liste de tous les articles, liste des catégories) sont construites dynamiquement en parcourant les fichiers du répertoire correspondant avec glob() ou scandir(). Le tri par date, le filtrage par catégorie et la pagination sont implémentés en PHP pur. Sur des sites contenant jusqu'à quelques centaines d'articles, les performances sont parfaitement comparables à une base de données relationnelle — et souvent supérieures grâce à l'OPcache qui garde les fichiers JSON en mémoire entre les requêtes.
cms/
├── content/
│ ├── pages/ # Pages statiques (un fichier JSON par page)
│ ├── posts/ # Articles de blog (un fichier JSON par article)
│ ├── categories/ # Catégories (un fichier JSON par catégorie)
│ ├── media/ # Fichiers uploadés (images, vidéos, polices)
│ ├── forms/ # Définitions de formulaires et soumissions
│ ├── redirects.json # Règles de redirections 301/302
│ ├── menu.json # Structure de navigation
│ └── settings.json # Configuration globale du site
├── core/ # Classes PHP du moteur (20 classes statiques)
├── themes/ # Thèmes installés
├── plugins/ # Plugins installés
├── admin/ # Interface d'administration (slug aléatoire)
└── index.php # Point d'entrée unique (routeur)Comprendre le cycle complet d'une requête dans QuietCMS permet de saisir la cohérence de l'architecture. Voici ce qui se passe entre le moment où un visiteur tape une URL et le moment où son navigateur reçoit le HTML :
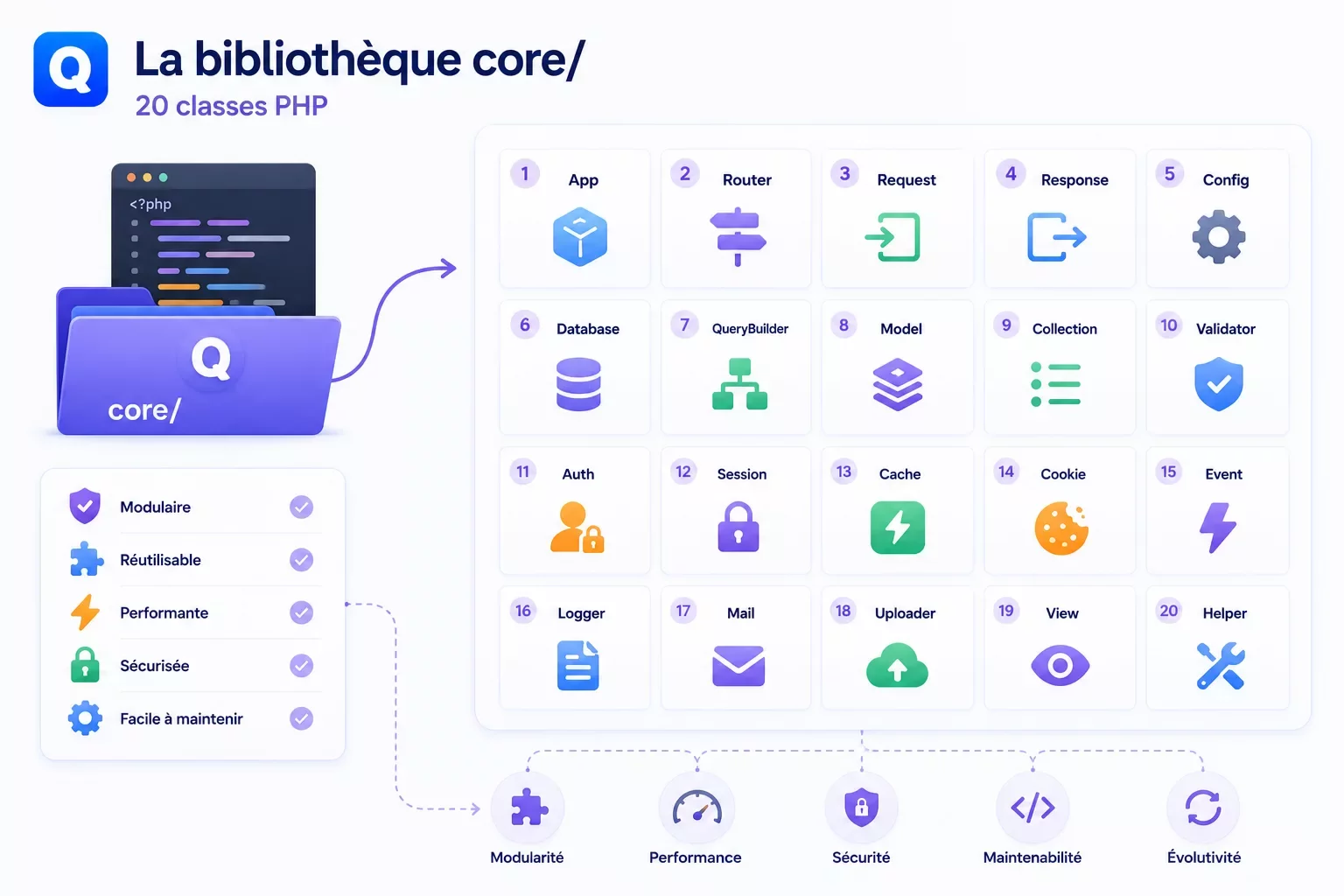
.htaccess ou la directive Nginx redirige toutes les URLs non-fichier vers index.php.index.php charge config.php (constantes : clé de chiffrement, slug admin, URLs), puis les classes core via require direct (pas d'autoloader PSR-4, pas de Composer).content/redirects.json. Si une règle correspond à l'URL courante, une réponse HTTP 301 ou 302 est émise immédiatement.content/.Content-Security-Policy, X-Frame-Options, Referrer-Policy…) configurés dans .htaccess.QuietCMS n'est pas un framework. C'est une bibliothèque de 20 classes PHP statiques, chacune avec une responsabilité unique et bien délimitée. Il n'y a pas d'injection de dépendances, pas de conteneur IoC, pas d'héritage complexe. Chaque classe peut être lue, comprise et modifiée indépendamment des autres.
ContentManager gère la lecture et l'écriture des entités JSON. Router résout les URLs. Security centralise le chiffrement, la sanitisation et les tokens CSRF. ThemeManager charge et rend les templates PHP. SitemapBuilder génère le sitemap XML. OpenGraphBuilder produit les balises Open Graph. JsonLD génère les données structurées Schema.org. PluginManager exécute les hooks. SidebarManager gère les sidebars et les widgets. FontManager injecte les polices @font-face.
Tour d'horizon des 20 classes PHP de la bibliothèque core/ de QuietCMS et leurs responsabilités.
Comment QuietCMS implémente un routeur PHP léger sans framework pour gérer les URLs propres.
Comment QuietCMS stocke tout le contenu en JSON sans base de données, avec les avantages et les limites du flat-file.
Les articles listés ci-dessus couvrent chaque composant architectural dans le détail. Mais comprendre l'architecture de QuietCMS, c'est aussi comprendre ce qu'elle n'est pas — et pourquoi c'est une force plutôt qu'une limitation.
QuietCMS ne dispose pas de cache de page HTML généré. Sur des sites à fort trafic, un reverse proxy comme Varnish ou Nginx FastCGI cache remplira ce rôle bien mieux qu'un cache applicatif maison. QuietCMS reste concentré sur ce qu'il fait bien : produire du HTML propre et sémantique depuis des fichiers JSON, sans couche d'abstraction inutile.
Il n'y a pas non plus de CLI de migration. Les "migrations" dans QuietCMS se font directement sur les fichiers JSON — soit manuellement, soit via un script PHP ad hoc de quelques lignes. Cette absence volontaire évite d'introduire un outil supplémentaire dans la chaîne de déploiement.
Il n'y a pas de système de queue ou de jobs asynchrones. Les opérations longues (conversion WebP, envoi d'email) se font de manière synchrone au moment de l'action. Pour les sites avec des volumes très élevés, un simple cron PHP peut prendre le relais si nécessaire.
Le stockage JSON flat-file atteint ses limites naturelles au-delà de quelques milliers d'articles, lorsque le parcours de tous les fichiers du répertoire posts/ pour construire une liste paginée commence à peser. En pratique, sur un serveur moderne avec SSD NVMe et OPcache PHP, ce seuil est bien au-delà de ce que la majorité des sites de contenu produiront jamais.
Pour ceux qui ont besoin de dépasser ce seuil, l'architecture de QuietCMS est conçue pour être extensible : un plugin peut intercepter les lectures de listes via les hooks disponibles et les remplacer par des requêtes vers un index Redis, un Elasticsearch ou une base SQLite — tout en laissant intact le reste du système (thèmes, SEO, administration, chiffrement).
Déployer QuietCMS se résume à trois opérations : copier les fichiers sur le serveur, pointer le virtual host vers le répertoire cms/, et visiter /install.php. Pas de configuration de base de données, pas de variables d'environnement critiques, pas de serveur de cache à démarrer. Le backup se fait avec rsync ou un simple zip du dossier. La restauration suit le même chemin inverse.
Cette simplicité opérationnelle a un impact direct sur la fiabilité : un système avec moins de composants a moins de points de défaillance. Un serveur PHP avec accès au système de fichiers est tout ce dont QuietCMS a besoin pour fonctionner — et cela se traduit par une disponibilité structurellement élevée, sans tuning ni monitoring complexe à mettre en place.
L'architecture de QuietCMS est intentionnellement conservative. Les pull requests qui ajoutent des dépendances externes, introduisent un framework ou complexifient le cycle de requête seront systématiquement refusées — non par dogmatisme, mais parce que la simplicité est la valeur fondatrice du projet. Les contributions bienvenues sont celles qui améliorent les performances, corrigent des bugs ou ajoutent des fonctionnalités utiles en restant dans le paradigme flat-file PHP natif.
L'objection la plus fréquente adressée aux CMS sans base de données concerne la concurrence : que se passe-t-il lorsque deux requêtes écrivent simultanément le même fichier ? QuietCMS répond à cette question avec un verrouillage explicite. Chaque écriture critique s'effectue avec un verrou exclusif, de sorte qu'une opération d'enregistrement ne puisse jamais entrelacer ses octets avec une autre. Les écritures de journaux, qui sont les plus fréquentes, utilisent un mode d'ajout atomique garantissant qu'une ligne est écrite d'un seul bloc.
Pour un site éditorial classique — un ou quelques administrateurs, un volume de visites modéré à élevé en lecture — ce modèle est parfaitement adapté. Les lectures sont massivement majoritaires et ne nécessitent aucun verrou, tandis que les écritures, bien plus rares, restent ponctuelles et sérialisées. L'architecture assume ce profil d'usage plutôt que de prétendre rivaliser avec un moteur transactionnel : elle est optimisée pour le cas réel d'un site de contenu, pas pour une application transactionnelle à fort taux d'écriture concurrente.
Contrairement à une intuition répandue, lire un fichier JSON sur un disque moderne est extrêmement rapide, souvent plus rapide qu'une requête vers une base de données distante qui implique l'ouverture d'une connexion, l'analyse d'une requête et un aller-retour réseau. QuietCMS exploite cet avantage en chargeant uniquement les fichiers nécessaires au rendu d'une page donnée. Il n'existe pas de schéma global à charger, pas de pool de connexions à gérer, pas de couche d'abstraction relationnelle à traverser.
Le système de fichiers du serveur joue par ailleurs le rôle d'un cache naturel : les fichiers fréquemment lus restent en mémoire au niveau du noyau, ce qui élimine de fait la plupart des accès disque réels. Couplée à la minification CSS, aux images responsives et au format WebP, cette légèreté structurelle se traduit par d'excellents scores de performance sans qu'aucune couche de cache applicative complexe ne soit nécessaire. La simplicité de l'architecture est ici directement responsable de sa rapidité.
L'architecture multilingue de QuietCMS distingue deux approches, choisies selon le besoin éditorial. Le premier modèle, dit contenu indépendant, stocke chaque langue dans son propre espace : les pages et articles d'une langue secondaire vivent dans une arborescence séparée et peuvent diverger totalement de la langue principale, tant sur le fond que sur la structure. Ce modèle convient lorsque les versions linguistiques ne sont pas de simples traductions mais des contenus pensés pour des audiences distinctes.
Le second modèle, dit traduction superposée, relie chaque traduction à son contenu d'origine. Le slug, la catégorie et la date restent ceux de la version source, et seule la matière textuelle change. Ce modèle est adapté à un site dont les versions linguistiques se correspondent une à une. Le fait que ces deux stratégies coexistent dans une même architecture flat-file, sans table de correspondance en base, illustre la flexibilité du stockage par fichiers : la relation entre langues est portée par la convention de nommage et par des métadonnées, pas par un schéma rigide.
Toute architecture a un domaine de validité, et l'honnêteté technique consiste à le nommer. Le flat-file de QuietCMS excelle de quelques pages à plusieurs milliers d'entrées de contenu. Au-delà, certaines opérations qui parcourent l'ensemble des fichiers — recherche plein texte, agrégations globales — voient leur coût croître linéairement avec le volume. Pour la quasi-totalité des sites éditoriaux, ce seuil n'est jamais atteint ; pour un site qui gérerait des dizaines de milliers d'articles avec des recherches complexes en temps réel, une base de données resterait plus appropriée.
QuietCMS fait donc un choix délibéré : viser le segment, très large, des sites de contenu où la simplicité, la portabilité et la sécurité priment sur la capacité à indexer des volumes massifs. C'est en refusant de tout faire que l'architecture conserve sa cohérence. Chaque fonctionnalité absente — couche ORM, pool de connexions, moteur de requêtes — est une dépendance en moins, une surface d'attaque en moins et une cause de panne en moins.
Le cœur de QuietCMS est organisé autour de classes à responsabilité unique, chacune dédiée à un domaine précis : gestion du contenu, des médias, de la sécurité, des polices, des redirections, du sitemap. Cette séparation nette facilite la lecture du code et limite les effets de bord : modifier la génération du sitemap n'impacte pas la gestion des commentaires. Pour un développeur qui reprend un projet QuietCMS, cette clarté réduit drastiquement le temps de compréhension, là où les frameworks à forte abstraction imposent souvent d'apprendre des conventions implicites avant de pouvoir intervenir.
La lisibilité n'est pas qu'un confort : c'est une propriété de sécurité et de pérennité. Un code que l'on comprend est un code que l'on peut auditer, corriger et faire évoluer en toute confiance. En misant sur des fichiers lisibles, une arborescence transparente et un noyau aux frontières nettes, l'architecture de QuietCMS fait le pari que la durabilité d'un site tient autant à la clarté de ses fondations qu'à la richesse de ses fonctionnalités.